$\color{blue}{\text{NOTE: Links to revelant external sources are provided as hyperlinks throughout this tutorial. Please click on them to learn more.}}$¶
During the past year, government agencies varied in their responses to COVID-19, however why such variability exists has yet to be fully understood. For example, the state of California was the first state in the United States to enact mandates to shelter in place in early 2020, whereas states that were in the Midwest or were Republican-led had less restricted responses. Furthermore, individual-level responses toward actions intended to mitigate COVID-19 have also varied with some individuals reacting hostilely toward impositions set by state- or company-level restriction (reference).
One factor that, in part, may impact both state- and individual-level responses to COVID-19—for example, whether to receive the COVID-19 vaccine or impose a mask mandate—could relate to people’s general inclinations to believe in conspiracy theories. Along with the very real threat of infectious disease posed by the pandemic, other contagions in the form of conspiracy theories have emerged. In their recent past (and present), Americans have confronted conspiracy theories from the validity of election results to the origins of COVID-19 to the government's alterior motives for enforcing certain public health directives. As the threat of consipracy theories and their effects are likely to continue, understanding psychological and behavioral factors associated with conspiracy theory susceptibility is essential.
One relevant open dataset called the “Measuring Belief In Conspiracy Theories" contains data that examined general conspiracist beliefs as measured by the 15-item Generic Conspiracist Beliefs Scale (GCBS), Big 5 personality constructs (TIPI), and demographic variables such as gender, age, education, and religious affiliation. The Generic Conspiracist Beliefs Scale is a novel psychological measure that assesses people's general inclinations toward engaging with conspiracy theories. These data were collected on approximately 2,495 respondents on the platform, Open Psychometrics, an open-source project that features several personality surveys.
*How does personality relate to conspiracist beliefs?*¶
**Current Research Questions**¶
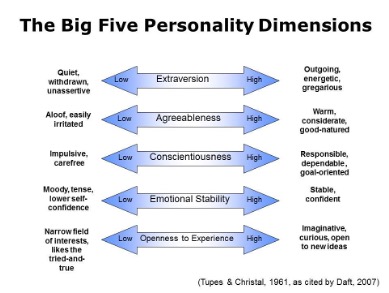
As part of this exploratory study, I intend to examine the potential role that Big 5 personality variables (i.e., openness to new experience, neuroticism, extraversion, conscientiousness, agreeableness) play in people's propensity to believe in or accept generic conspiracist beliefs, (as well as to the five factors produced by the GCBS (i.e., government malfeasance, extraterrestrial cover-up, malevolent global, personal well-being, control of information). Generally, which personality trait is most likely to be related to generic conspiracist beliefs, and how might that related to other variables such as age, gender, and religious orientation.
As I claimed in the introduction, conspiracy beliefs—with which Big 5 personality traits is likely to be associated—have led to differences in how people and states have reacted—not only to the COVID-19 pandemic—but also to other conspiracy theory-laden events, such as the 2020 presidential elections.
However, my previously mentioned individual-level dataset is limited in that it does not collect data on regioinal location of its participants. As I will describe for you soon, in order to answer my research questions related to state-level personality and conspiracist beliefs, I collected state-level data from three different data sources providing state-level Big-5 personality trait averages, along with other state-level variables including beliefs in specific conspiracy theory narratives and states' level of restrictedness in dealing with the pandemic.
To summarize, by the end of this tutorial, I hope to answer my research questions:
- How do Big-5 personality traits relate to people's general inclinations toward conspiracist beliefs?
- If there is an assocation, what type of unique effect does Openness have on those beliefs?
- At the state-level, how does personality relate to attitudes toward specific conspiracy beliefs?
- How does this relationship impact states' varied responses to the COVID-19 pandemic?
**Brief Introduction into the datasets**¶
I.) Individual-level Dataset: As mentioned previously, these data come from an open-source dataset on kaggle.com that collects measures of generic conspiracist beliefs, Big 5 traits, and other demographic measures.
Click here to go to section on ETL processing for this particular dataset.
This dataset is intended to be used to answer the research questions: "How do Big-5 personality traits relate to people's general inclinations toward conspiracist beliefs?", & "If there is an assocation, what type of unique effect does Openness have on those beliefs?".
II.) State-level Big-5 Averages: I initially procured these data off of a Wikipedia page that provided information from the following paper by Renfrow, Gosling, and Potter published in 2008 in Psychological Science. The first author, Dr. Peter J. Rentfrow, is well-known for his research in regionally-clustered psychological traits.
The Wikipedia page, as well as the published paper only provided standardized state means, state ranking, and sample sizes for each of the 50 US states and Washington D.C across all five personality traits.. I followed up with Dr. Rentfrow via e-mail who provided me with a .csv file of the raw means and standard deviations of their data (see State Means and SDs.csv in my GitHub website).
Click here to go to section on ETL processing for this particular dataset.
III.) State-level Beliefs in Conspiracy Theories: Given the novelty of the Generic Conspiracist Beliefs Scale, there were no state-level dataset (or individual-level dataset that could be aggregated by state) in order to mirror the Individual-level Dataset.
So, I searched through data collected in 2020 by the American National Election Studies (ANES). The ANES collects indiviudal-level data in the United States annually. Their survey data provide information on perceptions of different political candidates, social issues, and—as part of their 2020 wave—beliefs about various specific false narratives, which serve as a proxy to conspiracist beliefs for the purposes of my research questions. Examples of these narratives ask participants the extent to which they believe that vaccines cause autism or that COVID-19 was intentionally developed in a laboratory.
$\color{blue}{\text{NOTE: In order to access data from ANES, a registered account is required...It's free to register!}}$¶
I computed mean state-level variables by first grouping by state and then computing the mean composite. In addition to beliefs in false narratives, I retained state-level demographic variabels to control for like state-level political conservatism and highest level of education.
Click here to go to section on ETL processing for this particular dataset.
IV.) State-Level Non-Restrictive Responses to COVID-19 Indices: These data were collected on Wallethub.com from a table that scored all 50 US states and Washington D.C. on how least restrictive they were in response to the COVID-19 pandemic. In order to calculate state scores, 13 metrics were used using a scale from 1 to 100, with 100 indicating states that had the least restrictions. Metrics included states that did not require mask-wearing to states that prohibited large gatherings. Please read more about how these scores were calculated here.
Click here to go to section on ETL processing for this particular dataset.
II.) State-level Big-5 Averages, III.) State-level Beliefs in Conspiracy Theories, and IV.) State-Level Non-Restrictive Responses to COVID-19 Indices were merged to create my state-level dataset. Click here to go to the section on ETL processing for this particular dataset.
This dataset was used explore the last two research questions: At the state-level, how does personality—data from II.) State-level Big-5 Averages)—relate to attitudes toward specific conspiracy beliefs—(data from III.) State-level Beliefs in Conspiracy Theories)? & How does this relationship impact states' varied responses to the COVID-19 pandemic—(data from IV.) State-Level Non-Restrictive Responses to COVID-19 Indices)?